Mac arm启动Paddle Ocr记录(速度很慢不建议尝试)
截图
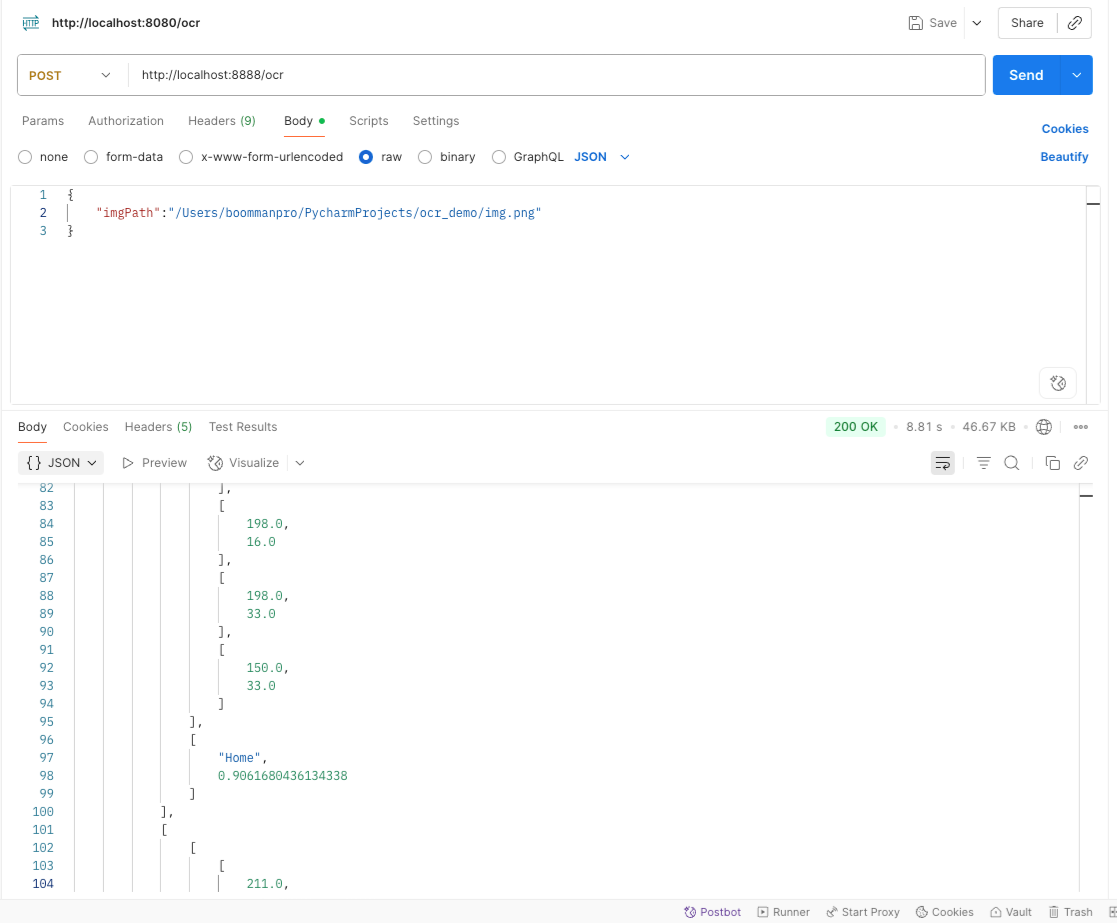
使用教程
# OCR Demo Project
这是一个基于PaddleOCR的OCR识别项目。
## 项目依赖
项目使用以下特定版本的依赖以确保兼容性:
- `paddlepaddle==2.6.0`
- `paddleocr==2.7.3`
- `numpy<2` (由于OpenCV等库与NumPy 2.x存在兼容性问题)
## 安装依赖
请使用以下命令安装项目依赖:
```bash
pip install -r requirements.txt
```
注意:NumPy版本必须低于2.0,因为OpenCV和其他依赖库与NumPy 2.x存在兼容性问题。
## 运行项目
使用以下命令运行项目:
```bash
python main.py
```
项目将在 `http://0.0.0.0:8888` 启动服务。
## API接口
### OCR识别接口
- URL: `/ocr`
- 方法: POST
- 参数: JSON格式,包含 `imgPath` 字段,值为图片路径
- 返回: JSON格式的OCR识别结果
示例请求:
```json
{
"imgPath": "/path/to/your/image.jpg"
}
```
## 性能优化
为了提高OCR识别速度,项目采用了以下优化措施:
1. 使用PP-OCRv3模型版本,相比v4版本速度更快
2. 禁用角度分类器(use_angle_cls=False),除非需要识别180度旋转的文本
3. 限制图像最大边长为960像素以加快处理速度
4. 关闭GPU使用(use_gpu=False),在Mac系统上更稳定且避免GPU初始化开销
5. 减少日志输出(show_log=False)
6. 启用多线程处理(cpu_threads参数),充分利用系统CPU资源
7. 增加文本识别批处理数量(rec_batch_num=10),提高批量处理效率
8. 调整检测阈值参数以平衡速度和准确率
9. 明确设置参数以消除警告信息
## 注意事项
1. 项目强制使用CPU运行(`use_gpu=False`),以避免在Mac系统上的段错误问题。
2. 如果遇到NumPy兼容性问题,请确保NumPy版本低于2.0。
3. 项目会自动下载OCR模型文件到用户目录下的 `.paddleocr` 文件夹中。
4. 默认禁用了角度分类器以提高处理速度,如有需要处理旋转文本的需求,可以启用该功能。
5. 通过明确设置参数,消除了"angle classifier is not initialized"的警告信息。
6. 在调用OCR时明确设置`cls=False`,避免运行时出现角度分类器相关警告。注意事项
paddlepaddle和paddleocr版本要固定
paddlepaddle==2.6.0
paddleocr==2.7.3
numpy<2脚本代码
import logging
import os
from flask import Flask, request, json, jsonify
from paddleocr import PaddleOCR
def init_log():
logging.basicConfig(format='%(asctime)s %(filename)s %(levelname)s %(message)s', datefmt='%a-%d-%b %Y %H:%M:%S',
level=logging.INFO)
file_handler = logging.FileHandler("ocr.log", encoding="utf-8")
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(logging.Formatter('%(asctime)s - %(filename)s - %(levelname)s - %(message)s'))
logger = logging.getLogger()
logger.handlers.append(file_handler)
init_log()
app = Flask(__name__)
# 获取CPU核心数,用于设置线程数
cpu_threads = os.cpu_count() if os.cpu_count() else 4
# 初始化OCR引擎,使用优化参数提高性能
# use_gpu=False 在Mac上更稳定,避免GPU初始化开销
# show_log=False 减少日志输出
# use_angle_cls=False 如果不需要处理180度旋转文本可以关闭以提高速度
# ocr_version="PP-OCRv3" 使用更快的模型版本
# 启用多线程处理以充分利用系统资源
ocr = PaddleOCR(
use_angle_cls=False,
use_gpu=False,
show_log=False,
ocr_version="PP-OCRv3",
# 限制图像尺寸以提高处理速度
det_limit_side_len=960,
det_limit_type='max',
# 启用多线程处理
det_db_score_mode="slow",
cpu_threads=cpu_threads,
# 文本识别参数
rec_batch_num=10,
# 明确禁用角度分类器以消除警告
use_textline_orientation=False,
# 其他优化参数
det_db_thresh=0.3,
det_db_box_thresh=0.5,
det_db_unclip_ratio=1.5,
det_cls_batch_num=10,
drop_score=0.5
)
# 通过POST方式识别图片,传入参数为图片的路径
@app.route('/ocr', methods=['POST'])
def learn_post_ocr():
try:
data = json.loads(request.data)
img_path = data['imgPath']
logging.info('ocr imgPath: %s', img_path)
# 明确设置cls=False以避免角度分类器警告
ocr_result = ocr.ocr(img_path, cls=False)
return jsonify({"code": 0, "msg": "ok", "data": ocr_result}), 200
except Exception as e:
logging.error('ocr error: %s', str(e))
ocr_result = {"code": -1, "msg": str(e)}
return jsonify(ocr_result), 200
if __name__ == '__main__':
# 可以返回中文字符
app.config['JSON_AS_ASCII'] = False
app.run(host='0.0.0.0', debug=True, port=8888)
License:
晋ICP备16009994号-1