AI相关系列二:部署GLM-OCR
背景
尝鲜GLM-OCR
结果仓库:https://github.com/boommanpro/glm-ocr-local-demo
过程中个人仅需要输出提示词,在github创建了仓库,然后就结束了😅
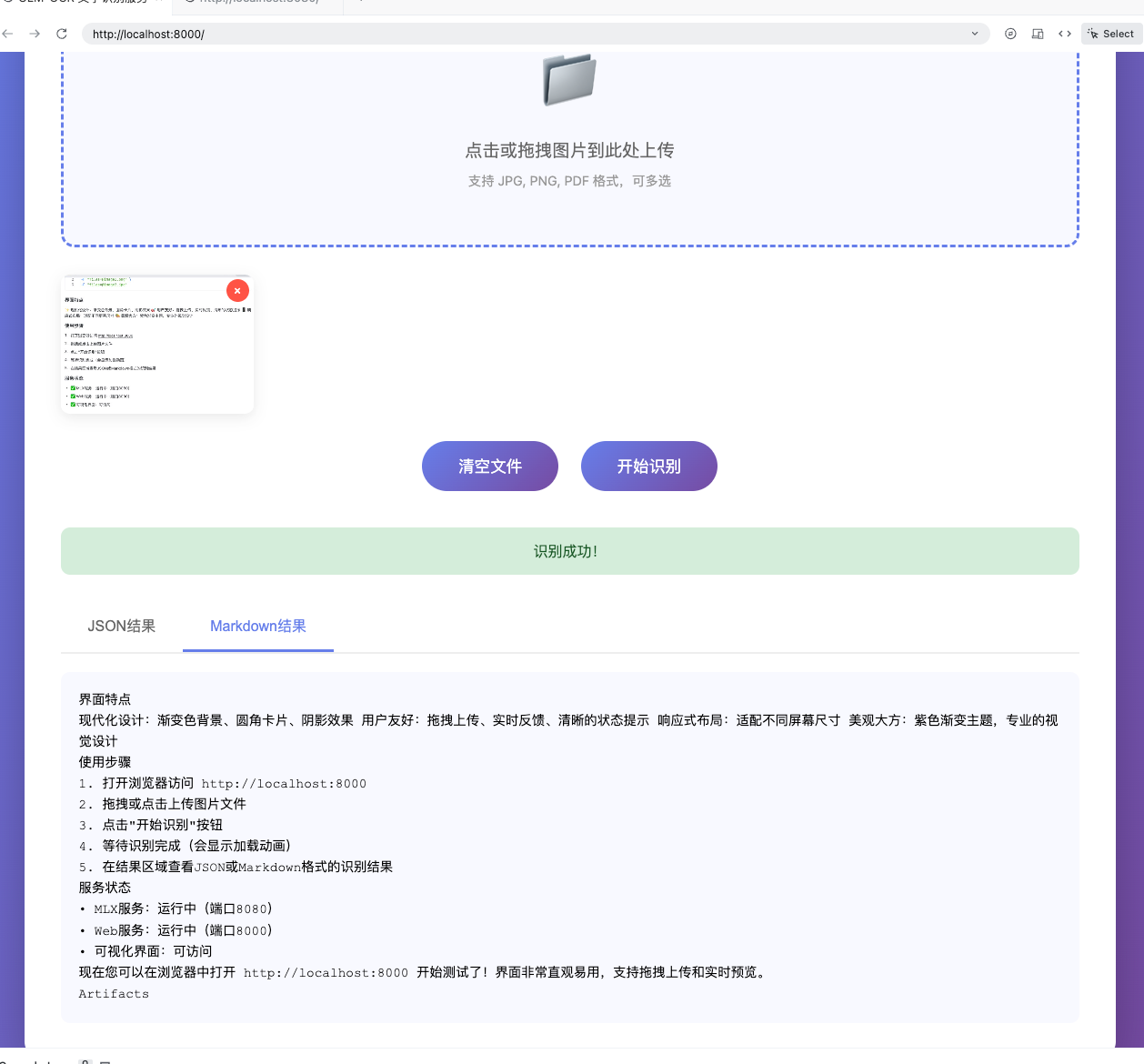
效果
测试图片:
系统截图
提示词
使用的是模型GLM-5,提示词如下:
制定一个完整的GLM-OCR安装、测试及Web服务部署计划,具体步骤如下:
1. 环境准备阶段:
- 检查当前电脑操作系统版本及Python环境(建议Python 3.8+)
- 确认系统是否已安装必要依赖(如Git、C++编译工具、CUDA等,根据GLM-OCR官方要求)
- 创建并激活Python虚拟环境以避免依赖冲突
2. GLM-OCR安装阶段:
- 从官方仓库克隆或下载GLM-OCR项目源码
- 按照官方文档安装项目所需的Python依赖包(使用requirements.txt)
- 下载预训练模型文件并放置到指定目录
- 执行安装验证命令,确保GLM-OCR核心功能可正常运行
3. Python测试阶段:
- 创建基础测试脚本,实现图片加载功能
- 调用GLM-OCR API对测试图片进行文字识别
- 验证识别结果的准确性和完整性
- 处理可能出现的异常情况(如图片格式不支持、模型加载失败等)
4. Web服务开发阶段:
- 选择合适的Web框架(如Flask或FastAPI)
- 设计并实现文件上传接口,支持常见图片格式(JPG、PNG等)
- 集成GLM-OCR识别功能到Web服务中
- 设计响应格式,确保识别结果以清晰的JSON格式返回
- 实现简单的前端页面,包含图片上传区域和结果展示区域
5. 系统测试与优化阶段:
- 测试Web服务的功能完整性(上传、识别、结果返回)
- 验证多图片并发处理能力
- 优化识别性能和响应速度
- 添加必要的错误处理和用户提示
6. 部署与文档阶段:
- 整理项目结构和运行说明
- 提供清晰的启动和停止服务的命令
- 记录已知问题及解决方案
请按照以上计划逐步实施,确保每个阶段完成后进行功能验证,再进入下一阶段。
我期望web服务不仅提供api接口,也提供可视化的web页面,供我进行测试,请实现
请优化项目结构,仅保持venv环境,以及最简化他人可部署结构即可,并且将readme写清楚。删除项目中的无用文件和目录
License:
晋ICP备16009994号-1