AICoding:为什么说 token 统计工作量不靠谱?
当"燃烧token"成为一门艺术
最近在 GitHub 上发现了一个有趣的项目 —— burn-token,它专门设计用来"烧掉"AI编码工具的token配额。这个项目的出现,恰好揭示了一个很多人忽视的事实:Token统计根本无法真实反映AI的工作量。
burn-token 是什么
简单来说,这是一个"激进"的token消耗技能,专为 Claude Code、Codex、Claude CLI 等AI编码助手设计。它通过无限循环的重度分析和计算,最大化token的消耗——即使你使用的是"无限"套餐。
项目提供了多种使用方式:
# 无限燃烧(默认)
/burn-token
# 按时间限制
/burn-token 1h
/burn-token 30m
# 按轮次限制
/burn-token 10 rounds
# 强制模式
/burn-token math # 强制数学模式/
burn-token 2h math # 时间限制 + 模式组合它的工作逻辑非常聪明:自动检测项目是否有代码——有代码就做代码分析,没代码就做数学题。每个任务都会读取所有项目文件到上下文中,而不是只读取相关文件,输出也要求至少2000字的详细分析。
KV Cache:Token统计的"水分"来源
要理解为什么token统计不靠谱,首先要理解现代AI推理的一个重要优化机制——KV Cache。
当你在和AI对话时,模型需要处理你输入的每个token,计算它的向量表示(Key和Value)。对于长对话,如果每次都要重新计算所有历史token,会非常浪费。所以推理引擎会缓存这些计算结果,这就是KV Cache。
这带来一个有趣的现象:重复的prompt前缀会被缓存命中,实际消耗的算力远少于token数量显示的那么高。比如你让AI分析一个代码库10次,如果prompt结构相似,它可能只是在缓存上做少量增量计算。
burn-token的核心创新正是针对这一点。它通过以下方式瓦解KV Cache:
纳秒级时间戳 — 每次调用都有独特的prefix
随机熵种子 — 从
/dev/urandom获取打乱任务顺序 — 每次执行顺序都不同
多变的措辞 — 每次用不同的词汇表达
轮换输出格式 — 这次用表格,下次用问答
这样一来,每个token都是新鲜计算的,没有缓存可用,token数量才能真正反映实际算力消耗。
为什么说"无限套餐"并不无限
很多人以为购买了Claude Max之类的"无限"计划就真的可以无限使用。但burn-token的FAQ里直接指出:
Claude Max计划有速率限制(rate limits),而不是真正的无限token。这个技能会持续冲击这些速率限制,配合缓存对抗机制,能最大化实际消耗。
所以"无限"更多是价格策略,而非技术上的无限制。Token统计只告诉你数字,却无法告诉你背后有多少是缓存贡献的"虚胖"。
如何从零开始制作类似项目
如果你想动手实现一个类似的token燃烧工具,需要理解几个核心模块:
1. 理解Agent Skill系统
burn-token本质上是一个Agent技能插件。以Claude Code为例,只需把SKILL.md放到指定目录:
mkdir -p ~/.claude/skills/burn-token
# 然后放入SKILL.md
Skill文件使用frontmatter定义元数据,主体是执行逻辑。2. 设计自动检测与分支逻辑
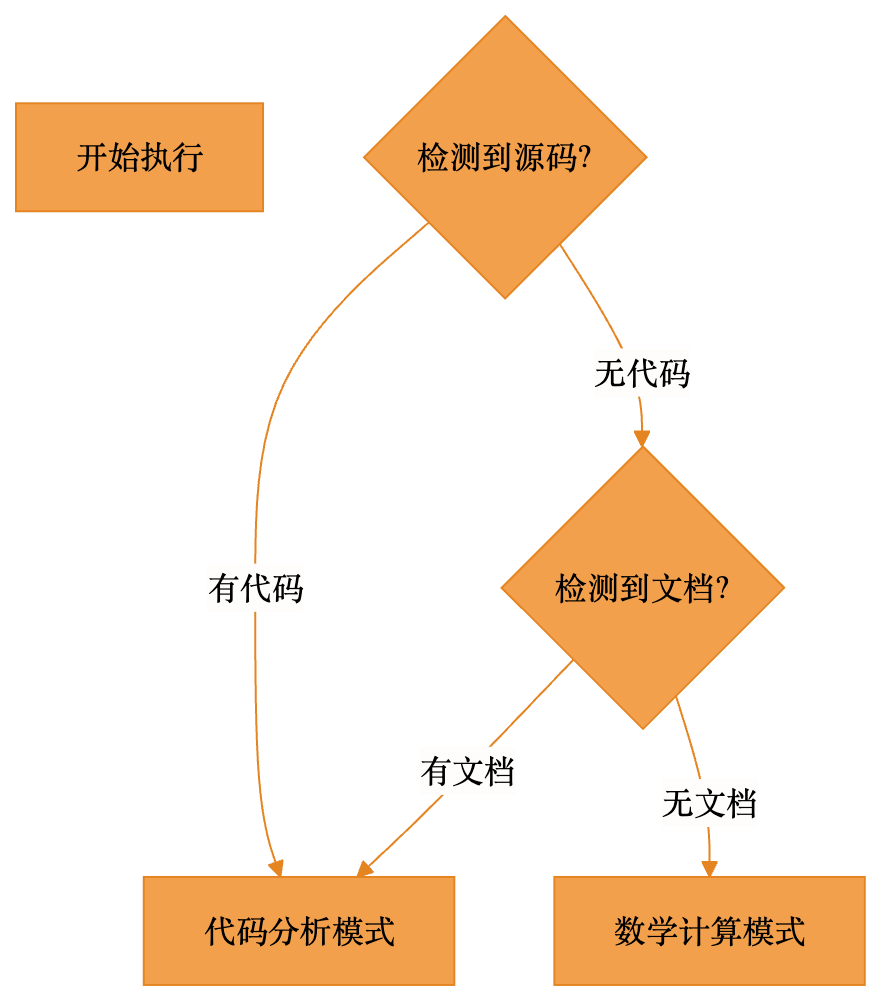
代码分析模式会进行架构审计、安全审计、性能分析、重构规划等工作;数学模式则处理数论、矩阵、微积分、组合数学等问题。
3. 实现KV Cache对抗
这是最关键的部分。你需要在每次请求中动态注入变化:
import time
import os
def generate_entropy_seed():
# 纳秒时间戳 + 随机数
return f"{time.time_ns()}{ord(os.urandom(1))}"同时改变任务顺序、措辞风格、输出格式,确保每次请求都是独一无二的。
4. 进度追踪与统计
需要实时显示燃烧进度:
=== BURN TOKEN === Round 1 | Task 3/10 | Elapsed: 0h12m | Est. tokens: ~48K | Seed: 2847193650 ===完成后汇总统计:
========================================
BURN TOKEN COMPLETE
Rounds: 7
Tasks: 70
Duration: 1h 58m 34s
Mode: code
Est. tokens burned: ~1120K
========================================
结语
burn-token项目给我们提供了一个独特的视角:token数量从来不是衡量AI工作量的可靠指标。缓存机制使得大量token是"免费的",而真正的计算成本隐藏在KV Cache的命中率背后。
理解这一点,对于评估AI系统的真实成本、设计更高效的提示策略、以及理解"无限"套餐的商业本质,都非常有帮助。如果你对这类底层机制感兴趣,不妨 clone 这个项目研究一下它的实现细节。